Adding Conditional Control to Text-to-Image Diffusion Models
Published:
- 论文链接:https://arxiv.org/abs/2302.05543
- 会议: ICCV23 Best Paper
- Keywords: Deeplearning, Diffusion Model
Abstract
提出了一种新的神经网络模型 ControlNet 支持额外添加控制条件来控制预训练的扩散模型。 ControlNet 以 end-to-end 的方式学习特定任务的 条件,即使训练的数据集很小(<50k),也可以得到一个稳健的模型。 此外,训练一个 ControlNet 和微调一个扩散模型的速度一样快,在个人的设备上即可训练;如果训练资源足够,则该模型可以扩展到大量的(millions to billons)数据集中。 论文中指出,像稳定扩散这样的大型扩散模型可以用 ControlNet 进行扩充,以支持边缘图、分割图、关键点等条件输入。这可能会丰富控制大型扩散模型的方法,并进一步促进相关应用。
1. Introduction
从 text-to-image 引出问题:
- 基于 prompt 的控制是否满足我们的需求?
- 在图像处理的许多任务中,都有着明确的公式,大模型能否应用于这些任务?
- 应该构建什么样的模型去处理广泛的问题条件和用户控制?
- 在特定的任务中,大模型是否能保留从数十亿张图片中获得的优势和能力?
ControlNet 将一个大型扩散模型的权值克隆成一个”trainable copy”和一个”locked copy”
- trainable copy: 保留了从数十亿张图片中学习到的网络能力
- locked copy: 在特定任务的数据集上进行训练,以学习控制条件
trainable copy 和 locked copy 使用一张名为 zero convolution 的特殊卷基层进行连接
具体的内容在后面的 Method 部分有详细讲述
2. Related Work
2.1 HyperNetwork and Neural Network Structure
起源于神经语言处理方法,训练一个小的 RNN 来影响一个大的神经网络权值。
引用文献: D. Ha, A. M. Dai, and Q. V. Le. Hypernetworks. In International Conference on Learning Representations, 2017.
2.2 Diffusion Probabilistic Model
2.3 Text-to-Image Diffusion
将扩散模型应用到 Text-to-Image 的任务当中,通常使用 CLIP 等预训练的语言模型将输入编码为潜在向量来实现。
2.4 Personalization,Customization, and Control of Pretrained Diffusion Model
2.5 Image-to-Image Translation
指出 ControlNet 与 Image-to-Image Translation 是不同的任务。
3. Method
\[y = F(x;\theta)\]上式指,神经网络 $F$ 使用一组参数 $\theta$ 将 $x$ 映射到 $y$ 中。 ControlNet 的做法是:
- 锁定 $\theta$ 中的所有参数,然后将其克隆到可训练的副本 $\theta_c$ 中,使用条件向量 $c$ 进行训练。(文章中将原始参数和新参数分别称为:locked copy, trained copy;制作这样的副本而不是直接训练原始权值的动机是为了在数据集较小时避免过拟合,并保持从数十亿张图像中学习的大型模型的能力)
- 连接神经网络块的是一种独特的卷基层,称为”zero convolution”,即权值和偏差都为零的 $1\times1$ 的卷基层。
模型图如下, 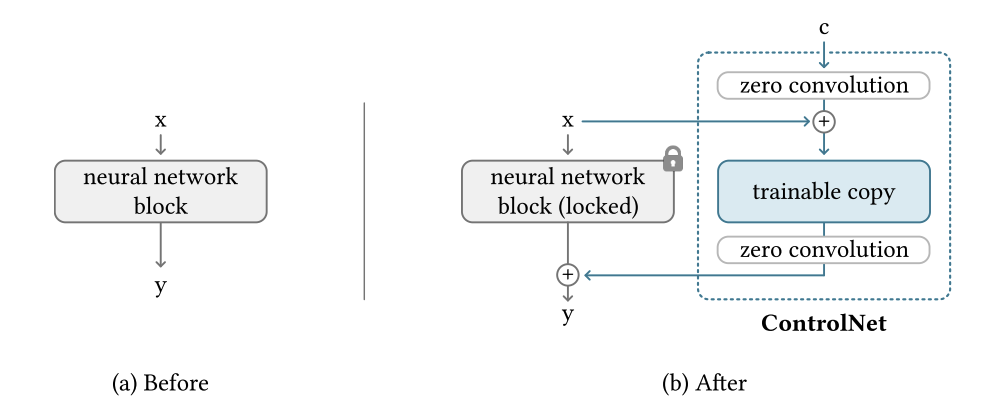
神经网络块的 train copy 和 locked copy 的所有输入和输出都与不存在 ControlNet 时的输入和输出一致。也就是说,当一个 ControlNet 应用于某些神经网络块时,在进行任何优化之前,不会对深层神经特征造成任何影响。 任何神经网络块的功能、功能和结果质量都得到了完美的保存,任何进一步的优化都将变得与微调一样快(与从头开始训练这些层相比)。
关于梯度推导这一部分内容没怎么看懂
3.2 ControlNet in Image Diffusion Model
首先介绍了 Stable Diffusion Model 的相关内容,具体可以参照下面这篇论文:
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models, 2021.
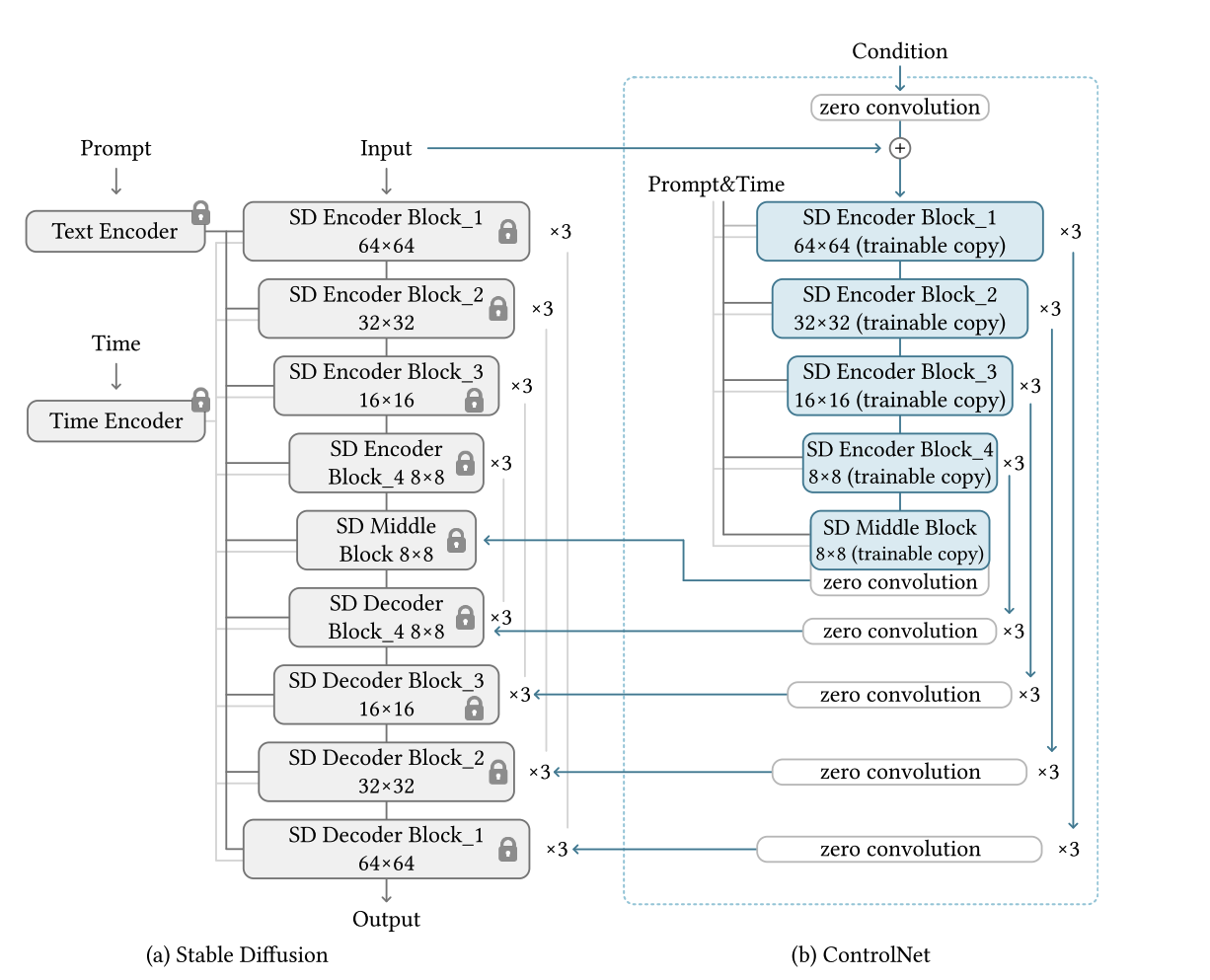
如上图所示,作者使用 ControlNet 来控制 U-Net 的各个层次。具体来说,作者使用 ControlNet 来创建12个编码块和1个稳定扩散的中间块的可训练副本。12个块有4种分辨率(64 × 64、32 × 32、16 × 16、8 × 8),每个块有3个。输出加到U-net的12个跳接和1个中间块中。
3.3 Training
3.4 Improved Training
几种应用于不同场景时的改进策略:
Small-Scale Training: 在计算设备有限的情况下,作者发现部分断开控制网与稳定扩散的连接可以加速收敛。默认情况下,将ControlNet连接到“SD Middle Block”和“SD Decoder Block 1,2,3,4”,如上图所示。作者发现,断开与解码器1、2、3、4的连接,只连接中间块,可以提高大约1.6倍的训练速度(在RTX 3070TI笔记本GPU上测试)。当模型显示出结果与条件之间的合理关联时,这些断开的环节可以在继续的训练中重新连接起来,便于准确控制。
Large-Scale Training: 由于过拟合的风险相对较低,可以首先训练ControlNets进行足够多的迭代(通常超过50k步),然后解锁Stable Diffusion的所有权值,并联合训练整个模型作为一个整体。这将导致一个更具体的问题模型。
3.5 Implementation
作者提出了以下几种基于不同图像条件的 ControlNet 实现:Canny Edge, Canny Edge (Alter), Hough Line, HED Boundary, User Sketching, Human Pose (Openpifpaf), Human Pose (Openpose), Semantic Segmentation (COCO), Semantic Segmentation (ADE20K), Depth (large-scale), Depth (small-scale), Normal Maps, Normal Maps (extended), Cartoon Line Drawing
Canny Edge效果图如下,其他实验结果图可参见原论文: 
4. Experiment
具体的实验设置,包括采样器的选择(DDIM),提示词的处理,学习率的设置,网络参数设置等等
5. Limitation
